CycleDistill: Bootstrapping Machine Translation using LLMs with Cyclical Distillation
By Deepon Halder, Thanmay Jayakumar, and Raj Dabre
Nilekani Centre at AI4Bharat, IIT Madras, IIT Bombay, IIEST Shibpur
Abstract
Large Language Models (LLMs) often fall short of dedicated systems for machine translation (MT), especially for low-resource languages where parallel data is scarce. This paper introduces CycleDistill, a novel bootstrapping approach that leverages LLMs to create high-quality MT systems with minimal data. By iteratively generating synthetic parallel data from monolingual text and using it to fine-tune the model, CycleDistill achieves significant improvements—boosting translation quality by 20-30 chrF points on average in the first iteration for three Indian languages, all without needing large parallel corpora.
The CycleDistill Framework
CycleDistill enhances low-resource MT through two innovative iterative distillation strategies. The core idea is to make a model teach itself to become better over several cycles.
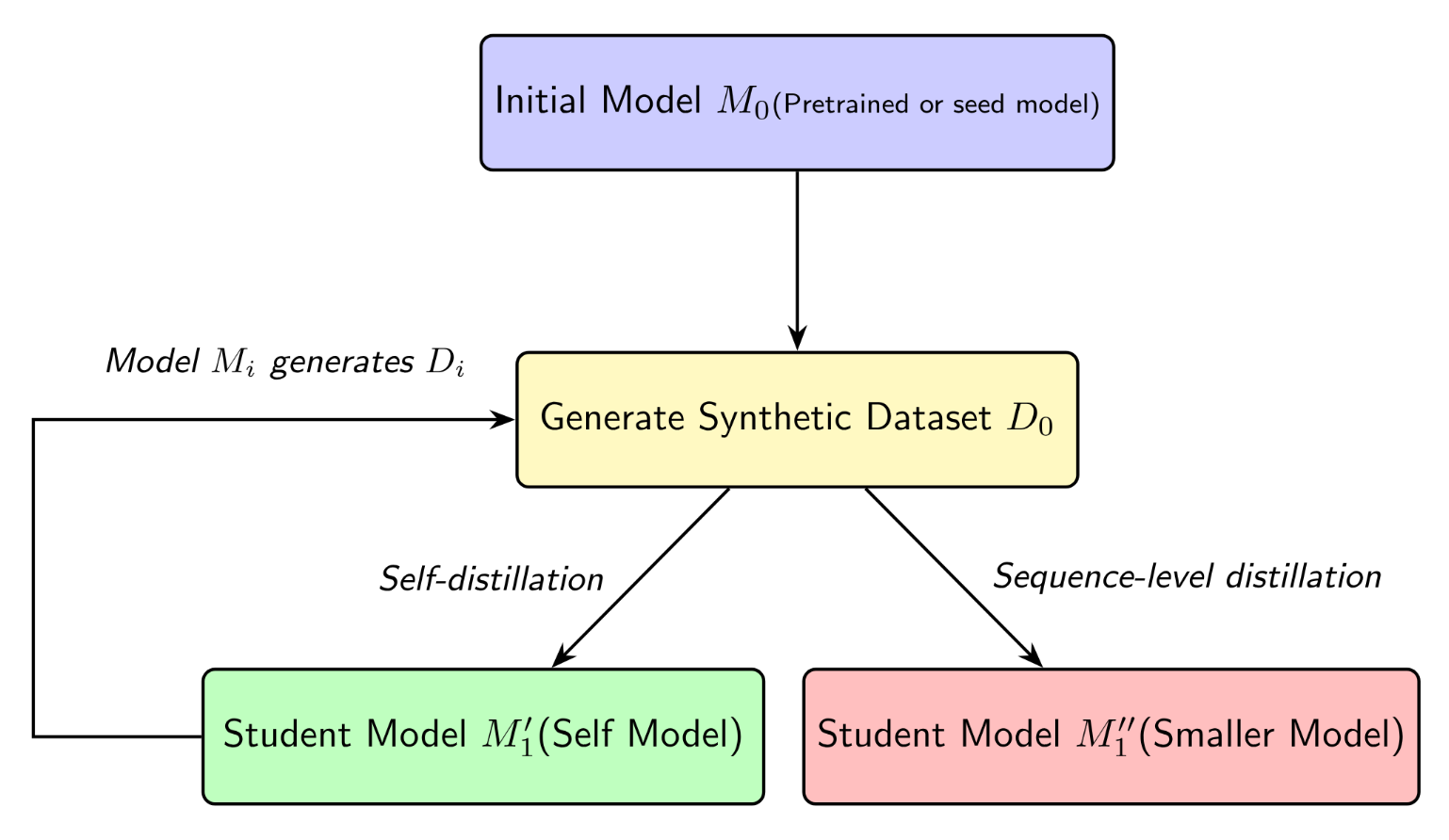
1. Iterative Synthetic Data Distillation
This is the foundational process where a model improves by learning from its own translations. The cycle is:
- Initialize: Start with a base pre-trained model (\(M_0\)).
- Generate: Use \(M_0\) to translate monolingual text, creating a synthetic parallel dataset (\(D_0\)).
- Distill: Fine-tune the model on \(D_0\) to create an improved model (\(M_1\)). This can be a same-sized model or a smaller, compressed one.
- Repeat: Use the improved model (\(M_1\)) to generate a new, better dataset (\(D_1\)) and repeat the cycle.
2. Soft Distribution-Preserving Distillation
-
Enhanced Data Extraction: During synthetic translation generation, for each token position \( t \), we record:
- The top-\( k \) token predictions (\( \{y_1^{(t)}, \ldots, y_{k}^{(t)}\} \))
- The corresponding softmax probabilities (\( \{p_1^{(t)}, \ldots, p_{k}^{(t)}\} \)), where \( \sum_{j=1}^{k} p_j^{(t)} \leq 1 \)
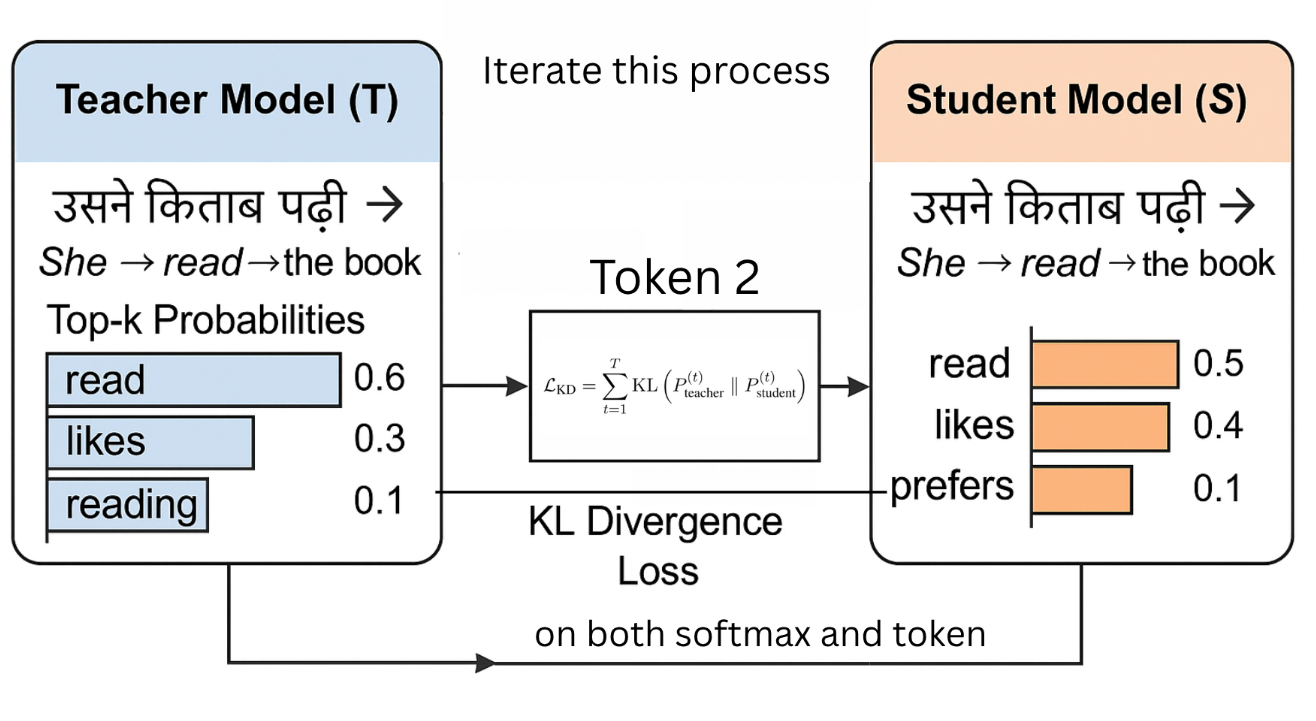
An Overview of the \textit{Soft Distribution Preserving Distillation}. - Logit-Based Distillation: The student model is trained to match not only the final output sequences but also the softmax distributions over the top-\( k \) tokens at each position. This is achieved by minimizing the Kullback-Leibler (KL) divergence loss: \[ \mathcal{L}_{\text{KD}} = \sum_{t=1}^{T} \mathrm{KL} \left( P^{(t)}_{\text{teacher}} \parallel P^{(t)}_{\text{student}} \right) \] where \( T \) denotes the sequence length, and \( P^{(t)} \) represents the softmax distributions. This approach enables the student model to more accurately approximate the teacher's behavior.
- Iterative Distillation: This process is also conducted over three iterations. In each cycle, the student from the previous round assumes the role of the new teacher, and a fresh synthetic dataset is generated, ensuring the transfer of rich token-level distributions.
Experiments
Models and Languages
Our study employs four language models of varying sizes from the LLaMA and Gemma families:
- Gemma 2 9B (\( G_{9B} \))
- Gemma 2 2B (\( G_{2B} \))
- LLaMA 3.1 8B (\( L_{8B} \))
- LLaMA 3.2 3B (\( L_{3B} \))
Each larger model undergoes distillation to produce both a refined same-size model and a compressed smaller model, adhering to established Sequence Distillation principles. Our evaluation encompasses three Indic languages:
- Hindi (\(HIN \))
- Bengali (\(BEN \))
- Malayalam (\(MAL \))
Distillation Process
For a given teacher model \( T \), distillation is performed to produce two student models:
- Same-size student (\( S_{\text{same}} \leftarrow T \))
- Smaller student (\( S_{\text{small}} \leftarrow T \))
The distillation relationships are formally expressed as: \[ G_{9B} \rightarrow \{ G'_{9B}, G_{2B} \}, \quad L_{8B} \rightarrow \{ L'_{8B}, L_{3B} \} \] where the refined large models (\( G'_{9B}, L'_{8B} \)) are subsequently utilized for synthetic data generation. We select \( k = 20 \) after empirical evaluation of the teacher models' output distributions revealed that the probability mass beyond the 20 highest-scoring tokens is negligible. We perform the experiments only upto three iterations (\( n = 3 \)). This limit was set because we observed that the performance gains stabilized after the third iteration. Further iterations yielded negligible improvements, indicating that the models were approaching a performance plateau, making additional computational cycles inefficient.
Training Data
Models are fine-tuned using the BPCC seed corpus, a parallel Indic-to-English dataset. Consistent with established practices in low-resource translation research, we randomly sample 20,000 sentence pairs for training and distillation. We use a fixed prompt format for all of the language and model pair, discussed in Figure 4.
Synthetic Data Generation
Following each distillation iteration, the most recent large model generates synthetic English translations for the original 20,000 source sentences. This synthetic data generation process is repeated for three complete cycles to enable progressive model refinement.
Evaluation
Model performance is assessed using the IN22 Gen corpus, the standard evaluation benchmark coupled with the BPCC seed corpus. The translation quality is quantified through chrF scores. This metric provides standardized measurement of n-gram translation accuracy, aligning with current best practices in machine translation evaluation.
Results and Analyses
Detailed Performance Metrics
The following tables present the comprehensive results from the paper, detailing chrF scores across all models, languages, and experimental settings. The data is broken down by model family for easier comparison. Click the buttons to toggle the visibility of the detailed data tables.
Table 1: Indic Languages
Column headers with (1) and (4) denote 1-shot and 4-shot settings. Unlabeled columns are 0-shot.
Main Results
Zero-Shot Setting
We observe a consistent performance trend across iterations of distillation. The first iteration results in a substantial performance increase. The second and third iteration usually have similar values with the first iteration, but we notice a small increase of 1-2% of chrF with each iteration. This pattern holds true for both iterative distillation and soft distribution-preserving distillation, with no significant differences observed between the two. However there are some notable results --
- For the Gemma 2B model with Bengali and the LLaMA 3B model with Malayalam, iterative distillation outperforms soft distribution-preserving distillation.
- In contrast, for the LLaMA 8B model with Hindi and the LLaMA 3B model with Bengali, soft distribution-preserving distillation demonstrates superior performance compared to iterative distillation.
One-Shot Setting
The one-shot setting yields the best overall performance, with the highest chrF scores observed exclusively in this configuration. The performance trend across iterations closely resembles that of the zero-shot setting. We observe some crossover between the two distillation methods, where one approach outperforms the other depending on the iteration count. Notable observations include:
- For the LLaMA 3B model on the Malayalam dataset, iterative distillation surpasses soft distribution-preserving distillation in performance.
- Conversely, for the LLaMA 3B model on the Bengali dataset, soft distribution-preserving distillation outperforms iterative distillation.
Four-Shot Setting
Performance declines slightly in the four-shot setting compared to earlier configurations, though iteration-wise differences remain minimal. Both iterative and soft distribution-preserving distillation exhibit similar gradual improvements and overall trends. This drop is primarily attributed to reduced contextual clarity due to increased input length, the four-shot prompt is approximately 60% longer than the one-shot, placing greater demands on the model's context window. Maintaining coherence across multiple examples becomes harder as prompts grow longer. The degradation is more pronounced in linguistically complex languages, suggesting that context dilution disproportionately affects grammatically rich targets. These results highlight the need to balance shot count and context efficiency in multilingual distillation, especially under limited model capacities.
Impact of Language Morphology on chrF
To further investigate the observed decline in 4-shot performance, particularly for morphologically rich languages, we visualize language-specific sensitivity to increasing shot settings. As shown in Table 1, we find a notable and steeper decline from 1-shot to 4-shot for Bengali and Malayalam, compared to Hindi, which supports the hypothesis that context dilution disproportionately impacts morphologically complex languages.
Effectiveness in Extremely Low Resource Languages
Study on Nepali
To assess the robustness and generalizability of our proposed method in low-resource or moderately known language settings, we conducted experiments using Meta's LLaMA 3.1 8B and LLaMA 3.2 3B models. We selected Nepali, written in the Devanagari script, as the target language. This language has partial representation in the model's pretraining corpus, which means the models possess a basic understanding of it and are capable of generating reasonable outputs, although it is not extensively covered. Despite this limited exposure, the models were able to produce useful distillation data. When we applied our method, we observed consistent improvements over baseline methods, as shown in Table 2. These results suggest that our method remains effective even when the target language has minimal presence in the training data. This demonstrates the potential of our approach to enhance performance in low-resource and cross-lingual generalization scenarios.
Study on Manipuri
The investigation included preliminary experiments on the Manipuri (Meitei script) to English translation task, utilizing several prominent large language models, specifically GPT-4, LLaMA 3.1 8B, and Gemma 2 9B. These models were evaluated for their ability to generate synthetic distillation data, which is the first step for the proposed CycleDistill framework. Results indicated a significant limitation: none of the evaluated models were capable of producing usable distillation data for Manipuri. This suggests that the process is inherently constrained in environments where the base large language model cannot effectively perform few-shot translation for the target low-resource language. Further detailed experiments were conducted on Manipuri (Meitei script) using the LLaMA 3.1 8B and LLaMA 3.2 3B models within the iterative distillation framework. As presented in Table 2, these results consistently showed no improvement in chrF scores across successive iterations.
Table 2: Low-Resource Languages (Nepali & Manipuri)
| Model | Iter | NEP | MNI | NEP(1) | MNI(1) | NEP(4) | MNI(4) |
|---|---|---|---|---|---|---|---|
| $L_{8B}$ | Base | 20.1 | 5.4 | 22.3 | 5.6 | 21.5 | 5.5 |
| DD_1 | 25.3 | 5.5 | 27.1 | 5.7 | 26.4 | 5.6 | |
| SD_1 | 24.8 | 5.4 | 26.9 | 5.6 | 26.1 | 5.5 | |
| DD_2 | 26.2 | 5.5 | 28.0 | 5.7 | 27.3 | 5.6 | |
| SD_2 | 25.9 | 5.4 | 27.8 | 5.6 | 27.0 | 5.5 | |
| DD_3 | 26.5 | 5.5 | 28.3 | 5.7 | 27.6 | 5.6 | |
| SD_3 | 26.3 | 5.4 | 28.1 | 5.6 | 27.4 | 5.5 | |
| $L_{3B}$ | Base | 15.2 | 4.1 | 17.4 | 4.3 | 16.8 | 4.2 |
| DD_1 | 20.4 | 4.2 | 22.1 | 4.4 | 21.5 | 4.3 | |
| SD_1 | 19.9 | 4.1 | 21.8 | 4.3 | 21.2 | 4.2 | |
| DD_2 | 21.3 | 4.2 | 23.0 | 4.4 | 22.4 | 4.3 | |
| SD_2 | 20.8 | 4.1 | 22.7 | 4.3 | 22.1 | 4.2 | |
| DD_3 | 21.6 | 4.2 | 23.3 | 4.4 | 22.7 | 4.3 | |
| SD_3 | 21.4 | 4.1 | 23.1 | 4.3 | 22.5 | 4.2 |
Column headers with (1) and (4) denote 1-shot and 4-shot settings. Unlabeled columns are 0-shot.
Further Analyses
Teacher Quality vs. Student Gain
Our analysis reveals that this relationship varies by shot setting. In zero-shot, a positive correlation holds, with higher teacher scores driving greater gains, validating distillation's reliance on data quality in example-free scenarios. In one-shot, correlation vanishes, as a single example anchors learning, making gains independent of teacher quality. In four-shot, gains are suppressed overall, due to context dilution and error propagation in longer prompts, positioning one-shot as the optimal for effective distillation.

Error Propagation and Recovery
A key limitation observed during our experiments is the susceptibility of the iterative framework to error propagation. Specifically, if an error such as the use of incorrectly generated or misaligned synthetic data is introduced at any iteration (for example, the second cycle), it can lead to a substantial degradation in performance, with declines of up to 30 to 40 chrF points observed in certain settings. These errors are compounded across subsequent iterations, as the model continues to self-distill based on flawed data, making recovery increasingly difficult. However, we also find that corrective interventions such as fine-tuning with accurately generated synthetic data can effectively mitigate such errors in subsequent iterations. This underscores the importance of early detection and correction of distillation errors, as well as the need for robust validation mechanisms during each cycle to prevent error amplification.
Performance of CycleDistill over Model Families
A key finding is the divergence in performance between LLaMA and Gemma models under CycleDistill. Gemma exhibits superior, robust learning, as compared to LLaMA.
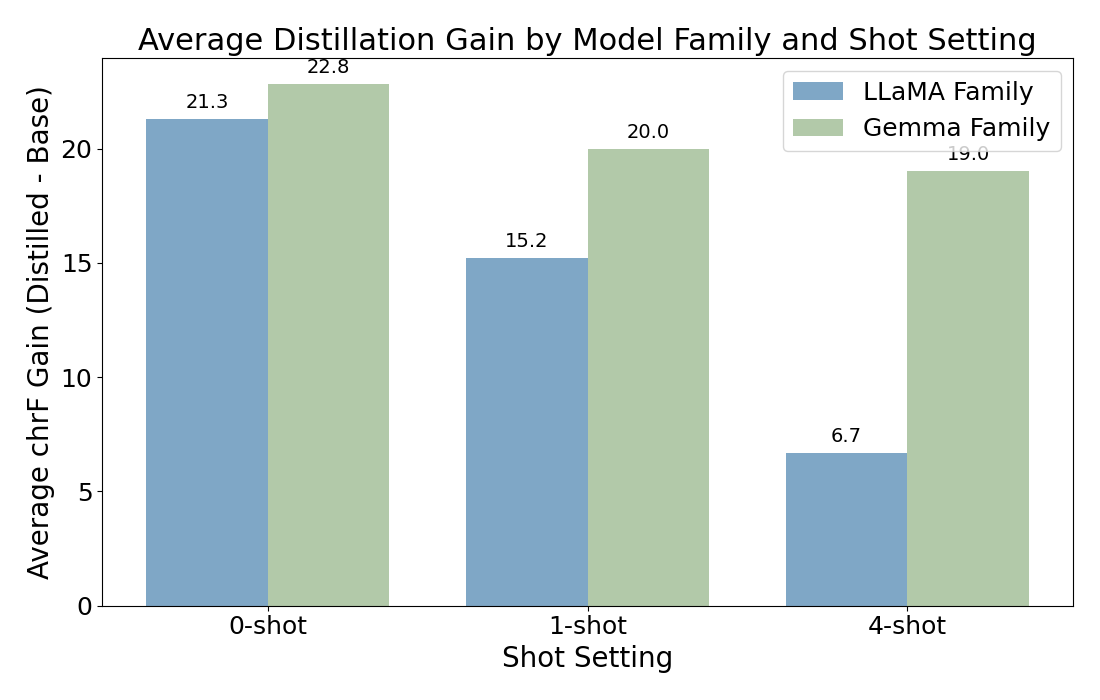
Efficiency of Knowledge Absorption across Model Families
The analysis of knowledge absorption rates reveals that the LLaMA 3B model exhibits a significantly higher efficiency in learning from its teacher compared to the Gemma 2B model. Specifically, the average absorption rate for LLaMA 3B is 1.190, while Gemma 2B achieves 0.628. This metric is defined as \[ \text{Absorption Rate} = \frac{\text{Student Peak Gain}}{\text{Teacher Base Score}} \] where Student Peak Gain is the maximum chrF improvement over the student's base score across distillation iterations and Teacher Base Score is the teacher's initial chrF score, is averaged across nine evaluation conditions (three languages and three shot settings). Although the Gemma family demonstrates superior absolute chrF scores, supported by a stronger teacher (Gemma 9B), the LLaMA 3B's higher absorption rate suggests it is a more efficient learner, particularly beneficial in resource-constrained distillation scenarios.
Conclusion and Limitations
Key Takeaways
- CycleDistill is a highly effective, data-efficient framework for low-resource MT.
- The largest performance gains come from the very first distillation cycle.
- The 1-shot setting provides the optimal balance of guidance and context for the model.
- The choice of the base model architecture (e.g., Gemma vs. LLaMA) significantly impacts the success of distillation.
- The framework enables both model refinement and compression without large parallel corpora.
Limitations
- Performance gains diminish significantly after two iterations.
- The method is vulnerable to error propagation if the synthetic data is flawed.
- The framework requires the base model to have at least a minimal few-shot translation ability for the target language to begin the process.
- Findings are currently limited to the tested Indic languages and model families.